如果是中心化的模型市場,只要有一個中心化的主體來組織模型的需求者和貢獻者形成市場即可,就像今天的淘寶市場一樣。但是,中心化的模型市場存在信任、安全、隱私保護、費用高等諸多問題。很難保證中心化主體的完全可信任、很難保證數據和模型的足夠安全,另外,一旦形成市場的壟斷,費用方面也會高于去中心化的解決方案。
Cortex的去中心化智能模型市場,涉及到模型的需求者、模型的貢獻者、礦工、全節點等。具體來說,它的基礎流程如下:
模型的貢獻者,全球的任何機器學習從業者都可以將訓練好的模型上傳到Cortex存儲層,而模型的需求者,例如dApp的開發者可以選擇適合自己的模型進行智能推斷,需求者需要支付費用給模型的上傳者和運行的全節點及記賬礦工。在執行推斷時,全節點從存儲層將數據和模型同步到本地,之后節點會通過Cortex的獨有虛擬機CVM(Cortex Virtual Machine)進行推斷,將推斷結果同步到所有全節點,并把結果返回給模型需求者。
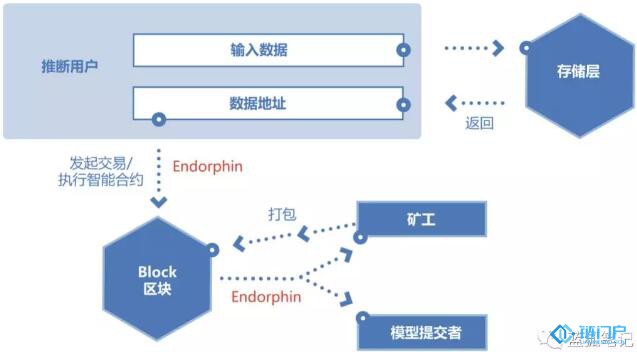
(推斷流程)
從上圖可以看出,用戶(模型的需求者)發起交易,也就是將需要預測的數據進行代入計算到所選取的數據模型進行數據推斷。執行帶有數據模型的智能合約和智能推斷都需要支付一定的費用,用Endorphin支付,每次支付的Endorphin數量跟模型運算難度和模型排名等相關,Endorphin價格由市場決定,它反映的是執行智能合約和進行模型推斷的成本。Endorphin類似于
以太坊的gas費用,Endorphin和CTXC(Cortex的代幣)存在動態轉換關系。
不過跟以太坊不同的是,Endorphin對應的CTXC會支付給兩部分人,一是該模型的貢獻者,二是礦工和全節點。
已有的智能合約如何獲得Cortex鏈上的模型能力?Cortex在已有的智能合約上添加額外Infer指令,也就是Cortex通過修改和擴展指令集,為智能合約增加
人工智能算法的支持,從而使得任何人都可以為自己的智能合約增加人工智能的模型。
上面簡單介紹了智能合約獲得人工智能能力的基本流程,那么其中的模型貢獻者是如何實現模型的提交的?
目前看,鏈上的處理能力還不足以進行數據的大規模訓練,基于這種現狀,Cortex提出了鏈下訓練的方案,它提供鏈下訓練的提交接口,也包括模型的指令解析虛擬機。
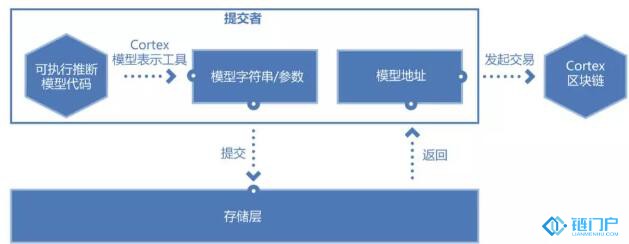
模型的貢獻者將模型通過Cortex的CVM解析成模型字符串及參數,并上傳到存儲層,發布通用接口,供模型的需求者(如dApp開發者)進行調用。這里有幾個問題需要解決:一是模型的質量;二是模型的存續;三是模型的防作弊;四是模型的挑選。
(模型提交流程)
為了防止有人泛濫提交模型,模型提交者需要支付一定的費用,同時也是支付其在存儲層存儲的費用,以保證其持續存在。如果模型提交者進行撤回操作,Cortex會根據模型的使用情況進行托管,這也是為了保證調用模型的智能合約能正常工作。Cortex上的模型是公開的,這意味著會存在抄襲和復制的可能,一旦出現明顯抄襲或復制,Cortex會通過介入仲裁的方式進行解決。
模型的挑選方面,Cortex鏈提供的開放的市場,不對模型進行限制。模型的需求者可根據某些數據進行挑選,如被調用次數等。也可以通過自定義的模型排序機制實現甄選,例如召回率、準確率、計算速度、基準排序數據集等。
Cortex除了為自己的用戶提供人工智能的服務,也為其他鏈提供AI的調用接口。比如,以太坊智能合約也可以調用其AI模型服務。
版權申明:本內容來自于互聯網,屬第三方匯集推薦平臺。本文的版權歸原作者所有,文章言論不代表鏈門戶的觀點,鏈門戶不承擔任何法律責任。如有侵權請聯系QQ:3341927519進行反饋。