在
區塊鏈系統中,共識算法作為保證分布式節點間數據一致性的算法,可以被分為兩大類,即概率一致性算法和絕對一致性算法。
概率一致性算法指在不同分布式節點之間,有較大概率保證節點間數據達到一致,但仍存在一定概率使得某些節點間數據不一致。
對于某一個數據點而言,數據在節點間不一致的概率會隨時間的推移逐漸降低至趨近于零,從而最終達到一致性。
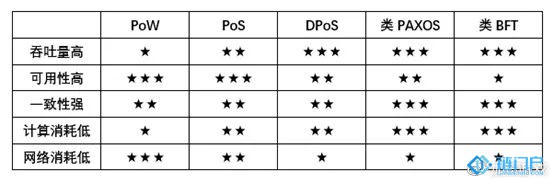
例如工作量證明算法(Proof of Work, PoW)、股份證明算法(Proof of Stake, PoS)和委托股權證明算法(Delegated Proof of Stake, DPoS)都屬于概率一致性算法。
而絕對一致性算法則指在任意時間點,不同分布式節點之間的數據都會保持絕對一致,不存在不同節點間數據不一致的情況。
例如分布式系統中常用的 PAXOS 算法及其衍生出的 RAFT 算法等,以及拜占庭容錯類算法(類 BFT 算法)。
一般而言,回顧上面所述 CAP 原理,概率一致性算法保證了系統的可用性而犧牲了系統的一致性,絕對一致性算法則與之相反,保證了系統的一致性而犧牲了系統的可用性。
各算法之間對比如下表,★ 數量越多,代表相應對比項表現越好。
迅雷鏈的業務需求保證分布式系統中的強一致性,并具備一定的容錯和防拜占庭節點作惡的能力,因此選擇類 BFT 算法作為共識算法。
我們在實用拜占庭容錯(PBFT)算法的基礎上,為了解決算法網絡消耗高的問題,作出了一些優化,提高了算法的可用性。
下面首先介紹區塊鏈中最常用的強一致性算法——實用拜占庭容錯(PBFT)算法。
假設系統中節點數量為 R=3f+1,其中f為系統中拜占庭節點的數量。
在發送消息的時候通過環境狀態、時間戳、請求、回復信息,客戶端同樣等待 2f+1 個回復,同時保證簽名、時間戳、回復信息來保證一致。
這里存在兩種情況,一種是客戶端請求超時,那就再發送一次,如果是主節點P出故障,那就改變環境狀態,新選一個 P 節點。保證第二次的執行過程。
在實際的算法流程中,PBFT 算法定義三個任務階段:預準備(pre-prepare)、準備(prepare)、確認(commit)。
預準備:P 分配一個系統序列號 ID,發送給所有 B 節點。
發送格式(環境狀態、ID、信息摘要、客戶端請求)。B 節點驗證信息摘要和客戶端請求一致,驗證當前環境狀態編號。
準備:B 節點在接收信息后加上自己的消息日志,發送至其余節點。P 和 B 節點同時驗證消息簽名,如果一致,那么就把驗證通過寫入消息日志。每個節點在準備階段對每個副本節點驗證預準備的消息和準備消息一致性檢查完畢。
確認:在前面兩個極端一切正常的話,在同一系統環境中,所有請求序號一致,驗證消息一致,簡單理解就是確認 2f+1 個節點發送了之前發送的序號和消息。
每個節點接受確認消息,簽名正確;消息的系統環境編號V與節點的環境編號 V 一致;消息的序號 ID 滿足序列要求。節點通過確認至少 2f+1 個副本信息,保證整個系統中算法的正確性。
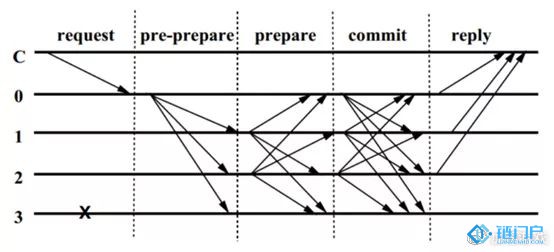
圖中,C 我們認為是客戶端,0、1、2、3 是分布式系統中的節點成員,其中由 0 節點提議區塊,1、2、3 節點對提議出來的區塊進行投票,其中 3 節點已發生故障。我們默認 3 發送信息為無效。那么 PBFT 算法執行的流程如下:
1. C 發起一筆請求到 0 號節點。
2. 節點 0 開始對請求排序編號,并把請求序號發送到 1、2、3 節點。
3. 1、2 節點互相之間和 0 節點之間發送消息。
4. 0、1、2 之間確認 0 節點的分配序號,互相確認。
5. 0、1、2 確認信息回復 C。
6. 客戶端 C 判斷收到確認是否在 2f+1 內,確認結果。
在每一輪共識分三個階段達成共識:Pre-Prepare、Prepare 和 Commit,整個流程如下:
1. 從全網節點選舉出一個提議節點(Proposer),新區塊由提議節點負責生成。
2. 每個節點把客戶端發來的交易向全網廣播,提議節點將從網絡收集到需放在新區塊內的多個交易排序后存入列表,并將該列表向全網廣播。
3. 每個節點接收到交易列表后,根據排序模擬執行這些交易。所有交易執行完后,基于交易結果計算新區塊的哈希摘要,并向全網廣播。
4. 如果一個節點收到的 2f 條來自其它節點發來的摘要都和自己的相同,就向全網廣播一條 commit 消息。
5. 如果一個節點收到 2f+1 條 commit 消息,即可提交新區塊及其交易到本地的區塊鏈和狀態數據庫。
版權申明:本內容來自于互聯網,屬第三方匯集推薦平臺。本文的版權歸原作者所有,文章言論不代表鏈門戶的觀點,鏈門戶不承擔任何法律責任。如有侵權請聯系QQ:3341927519進行反饋。