火幣區塊鏈應用研究院對EOSIO的Dawn 3.0版本在測試環境中通過多個場景的測試對比進行了平臺性能的研究分析。
基于測試條件下(局域網環境內的AWS服務器)的EOSIO最大能達到1900 TPS。這與Dawn 3.0說明文檔中的平均TPS(3000)、最優TPS(6000)和理論最優TPS(8000)仍有差距,但可穩定達到文檔所述最差情況下1000 TPS
隨著服務器配置的提升,系統最大TPS會隨之提高。同時,在條件允許的情況下,增加超級節點(Block Producer)的服務器資源,可得到更好的整體性能。因此在主網環境下,建議為節點使用盡可能高配置的服務器
去中心化部署會對性能有不利影響。由于目前EOSIO的程序代碼還不支持多線程,因此只能使用單核CPU,暫時無法利用并行計算提高效率。在此情況下,去中心化的部署尤其是增加超級節點并不會因分攤單個服務器壓力而提高性能,反而會增加CPU開銷,并可能對TPS產生影響
合理使用JIT會有一定性能提升。該方式可降低CPU使用率并提高一定程度的TPS,但需注意對穩定性的影響。
目前EOS超級節點競選活動仍在如火如荼的進行當中。據統計,截止5月2日,目前活躍的競選組織有102個。與此同時,block.one在4月份發布了EOSIO的Dawn 3.0版本,并計劃于6月份上線主網。
此前眾多社區已組建了測試網絡,并對EOSIO性能尤其是每秒能處理交易數量(TPS)進行了測試。但TPS性能受制于編譯參數、服務器硬件、操作系統、網絡等諸多條件,測試出來的結果更多的是實驗室條件下的“理論油耗”(參考 https://steemit.com/cn/@eoseoul/bmt-eosio-tps-by-eoseoul-block-one-jit)。
因此與此前的很多測試不同,火幣區塊鏈應用研究院本次的研究分析并不是圍繞EOSIO是否能達到Dan Larimer團隊所宣稱的1M TPS展開,而是通過分析Dawn3.0在不同條件下觀測到的性能指標,對未來主網架構及服務器配置等提出思路與建議。后續如果有新版本例如Dawn4.0等,火幣區塊鏈應用研究院會繼續跟進研究。
另外需要注意的是:測試得到的指標數據結果不是也不應被視為是對EOSIO平臺或項目最終效果的證明或確認。特此聲明。
經過測試結果與分析研究,我們得到以下主要結論及技術建議:
基于我們測試條件下(局域網環境內的AWS服務器)的EOSIO最大能達到1900 TPS,與Dawn 3.0說明文檔(參考https://medium.com/eosio/eosio-dawn-3-0-now-available-49a3b99242d7)中的平均TPS(3000)、最優TPS(6000)和理論最優TPS(8000)仍有差距,但可穩定達到文檔所述最差情況下1000 TPS。
隨著服務器配置的提升,系統最大TPS會隨之提高。同時,在條件允許的情況下,增加超級節點(Block Producer)的服務器資源,可得到更好的整體性能。因此在主網環境下,建議為節點使用盡可能高配置的服務器。
由于目前EOSIO的程序代碼還不支持多線程,因此只能使用單核CPU,暫時無法利用并行計算提高效率。在此情況下,去中心化的部署尤其是增加超級節點并不會因分攤單個服務器壓力而提高性能,反而會增加CPU開銷,并可能對TPS產生影響。
合理使用JIT可降低CPU使用率并提高一定程度的TPS,但需注意對穩定性的影響。
3.1 測試程序版本
測試程序為EOSIO的dawn-v3.0.0版本
3.2 測試硬件環境
亞馬遜AWS,型號按照配置高低主要有以下兩種:
AWS EC2 t2.large(下文簡稱低配服務器): 2 核 2.3 GHz, Intel Broadwell E5-2686v4 CPU, 8GB內存
AWS EC2 C5.4xlarge(下文簡稱高配服務器): 16 核 3GHz, Intel Xeon Platinum 8124M CPU,32GB內存
服務器間為10Gbps局域網網絡,通訊延遲(ping)小于1ms
操作系統為Ubuntu 16.04
3.3 測試方法及工具
使用block.one提供的txn_test_gen測試插件工具發送測試交易數據并觀察實際TPS與系統CPU使用率等指標情況。(參考https://github.com/EOSIO/eos/wiki/Testnet-Single-Host-Multinode與https://gist.github.com/spoonincode/fca5658326837b76fd744d39b2a25b4e)
4.1 場景1
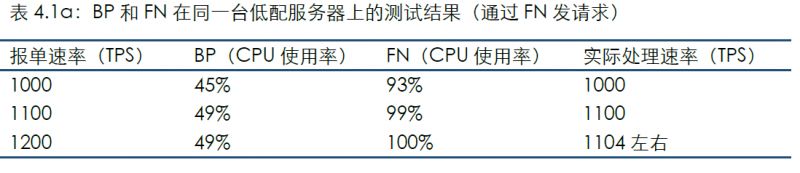
將1個“超級節點”(Block Producer,以下簡稱BP)和1個普通節點(Full Node,以下簡稱FN)部署在同一臺低配服務器上。
通過連接FN發送測試數據的結果如下:
通過連接BP發送測試數據的結果如下:
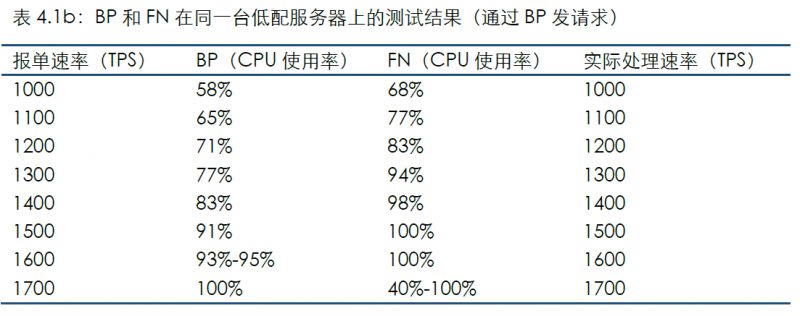
值得注意的是,當報單速率為1700時,雖然BP的CPU已100%使用,但BP可穩定處理;同時FN進程所在CPU的使用率起伏較大,無法及時從BP同步到區塊,并且隨著系統運行,BP與FN之間的區塊高度差距會越拉越大。
通過該場景的結果可發現:
由于目前EOSIO的程序還不支持多線程,因此暫時無法利用多核CPU的并行計算提高效率;
BP的CPU使用率低于FN,似乎與通常對“超級節點”的認識相反。這原因可能是因為上述兩種節點所承擔的工作不同:BP設計理念是為了保證交易安全性和完整性(不丟失區塊),而FN被設計為對外提供服務,需要進行交易簽名、序列化、驗證等等;
報單分別通過BP和FN發送時,平臺TPS有顯著差異,這也與上述需要處理交易的簽名、序列化等工作有關。
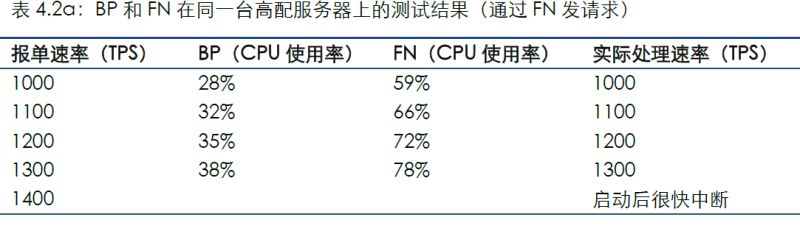
4.2 場景2
提高服務器配置,繼續觀察系統性能。將1個Block Producer(以下簡稱BP)和1個Full Node(以下簡稱FN)部署在同一臺高配服務器上。
通過連接FN發送測試數據的結果如下:
通過連接BP發送測試數據的結果如下:
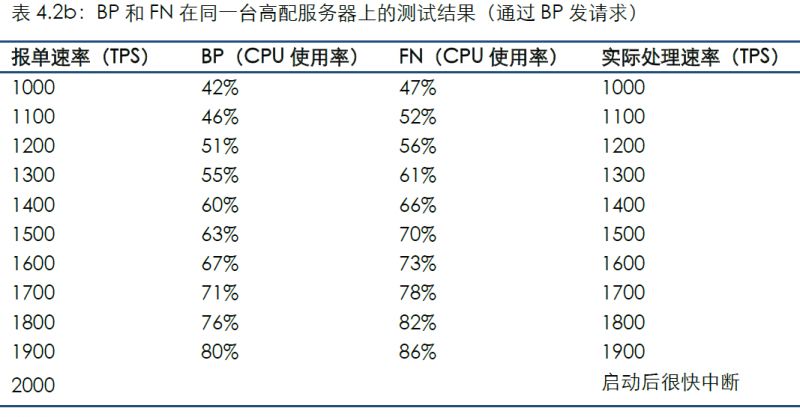 對比場景1可看到,隨著服務器配置的提升,系統最大TPS會隨之提高。
對比場景1可看到,隨著服務器配置的提升,系統最大TPS會隨之提高。
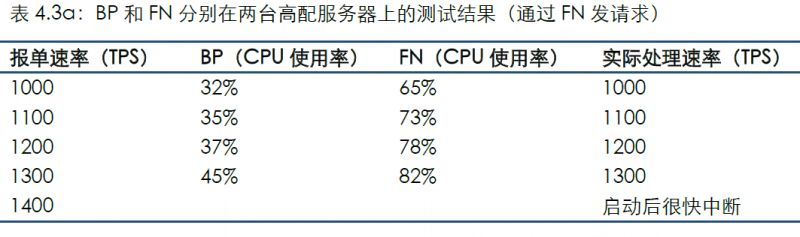
4.3 場景3
以上場景是將BP和FN部署在同一臺服務器上,而本場景是將BP和FN分別部署在兩臺高配服務器上。
通過連接FN發送測試數據的結果如下:
通過連接BP發送測試數據的結果如下:
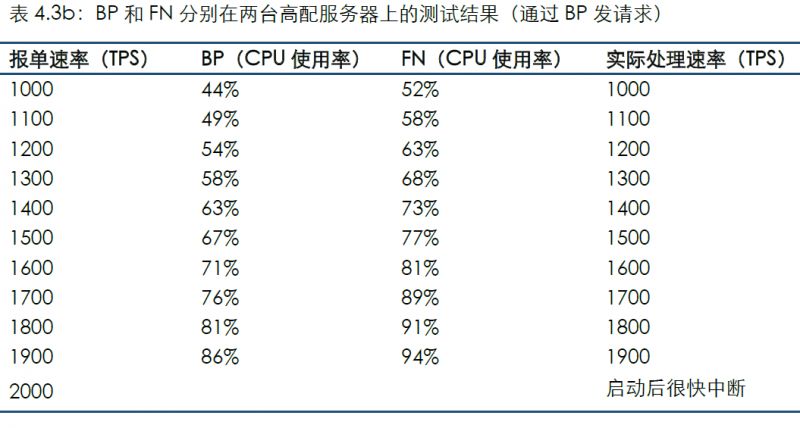 對比場景2可看到,本場景中的CPU使用率與同條件相比略微提高,應為處理網絡通訊的開銷;分別部署并未顯著影響TPS,這也與目前單線程方式有關:BP和FN部署在同一臺服務器上并不會爭奪CPU資源,因此在當前代碼未支持多線程的情況下分開部署有可能并不會因分攤壓力而提高性能,反而略微增加了CPU開銷。
對比場景2可看到,本場景中的CPU使用率與同條件相比略微提高,應為處理網絡通訊的開銷;分別部署并未顯著影響TPS,這也與目前單線程方式有關:BP和FN部署在同一臺服務器上并不會爭奪CPU資源,因此在當前代碼未支持多線程的情況下分開部署有可能并不會因分攤壓力而提高性能,反而略微增加了CPU開銷。
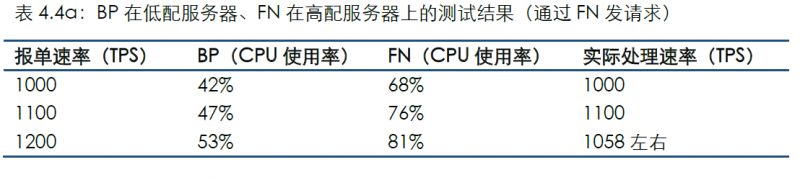
4.4 場景4
以上場景是將BP和FN分別部署在同一配置服務器上,而場景4與場景5是將BP和FN分別部署在不同配置的服務器上。本場景是BP部署在低配服務器上,FN部署在高配服務器上
通過連接FN發送測試數據的結果如下:
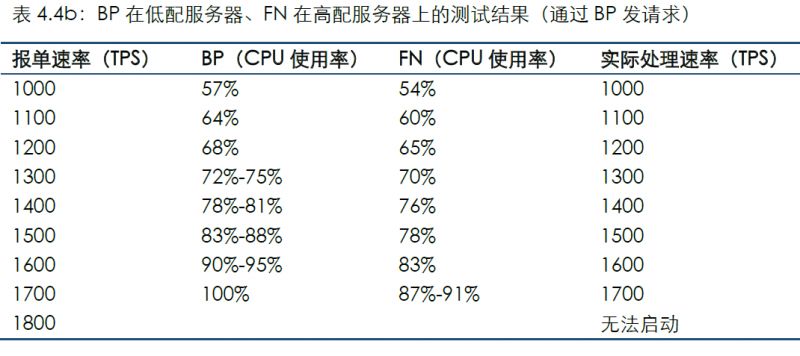
 通過連接BP發送測試數據的結果如下:
通過連接BP發送測試數據的結果如下:
4.5 場景5
本場景是BP部署在高配服務器上,FN部署在低配服務器上。
通過連接FN發送測試數據的結果如下:
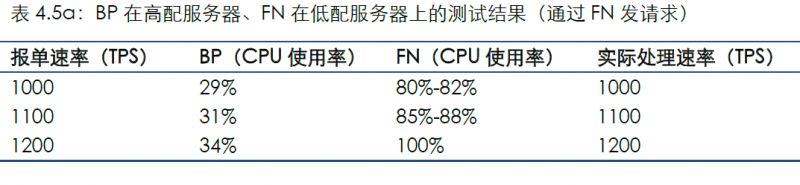 通過連接BP發送測試數據的結果如下:
通過連接BP發送測試數據的結果如下:
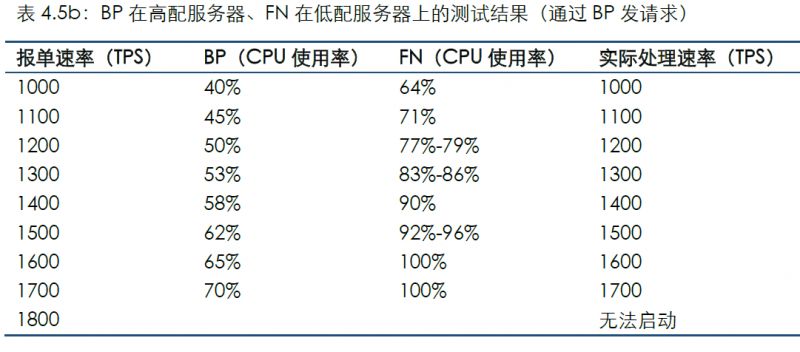
對比場景4和場景5,在條件允許的情況下,為BP分配更多的資源,可得到更好的整體性能。
4.6 場景6
以上場景是兩臺服務器的情況(1個BP、1個FN)。增加1個FN后,本場景為1個BP、2個FN分別部署在3臺高配服務器上。
通過連接FN發送測試數據的結果如下:
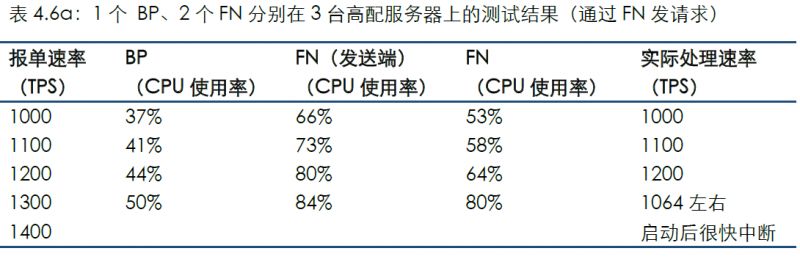 通過連接BP發送測試數據的結果如下:
通過連接BP發送測試數據的結果如下:
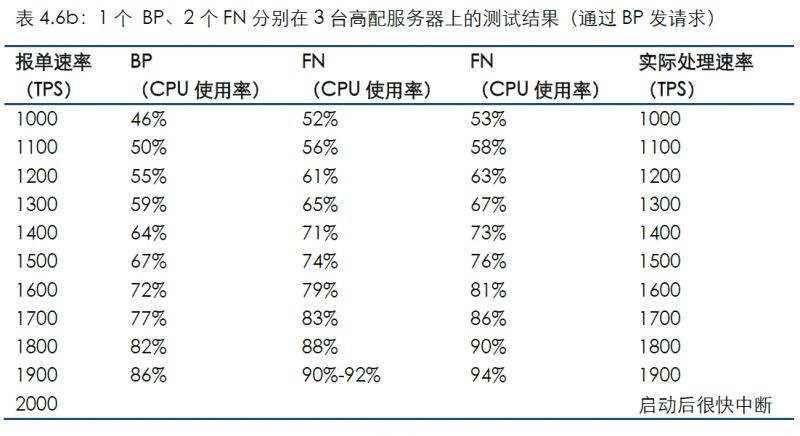
對比場景2的結果可看到,在單線程情況下增加服務器會提高CPU開銷,并可能對TPS產生影響。
4.7 場景7
以上場景是單個BP的情況。我們在本場景中增加節點為2個BP和2個FN并觀察結果。
通過連接FN發送測試數據的結果如下:
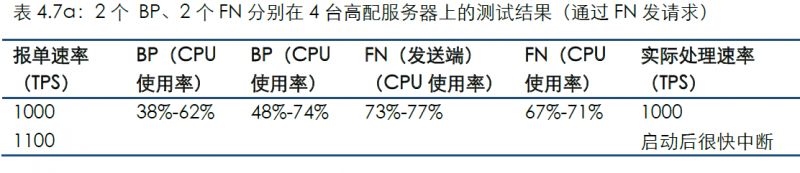 通過連接BP發送測試數據的結果如下:
通過連接BP發送測試數據的結果如下:
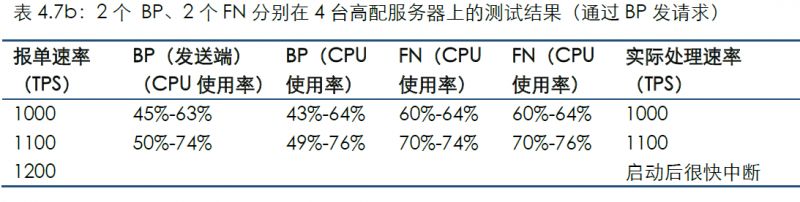
對比場景6可看到,同等情況下的CPU使用率會增高,同時所能達到的最大TPS也有較大幅度的降低,表明增加BP會對性能有較大影響。如果在多節點分布在異地的主網環境中,還會疊加網絡延遲等更為復雜的環境因素。這對節點服務器資源提出更高要求。
4.8 場景8
另外,在Dawn 3.0描述文件中提到了本版本的默認解釋器從JIT改為了Binaryen WebAssembly,這會降低性能但帶來穩定性的提高并降低編譯智能合約時的延遲。我們對場景2的運行參數改為JIT并觀察結果。
通過連接FN發送測試數據的結果如下:
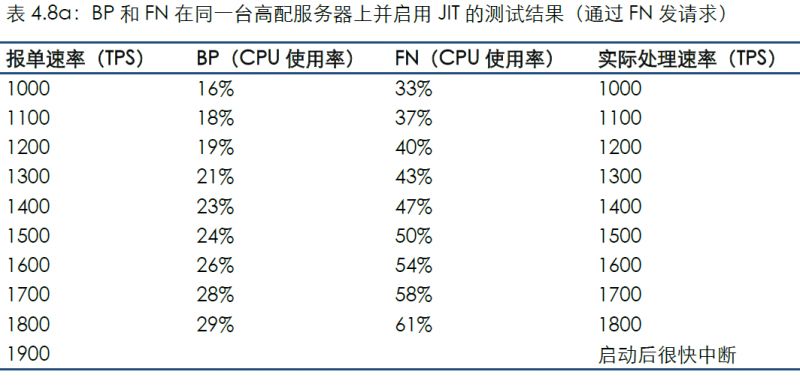 通過連接BP發送測試數據的結果如下:
通過連接BP發送測試數據的結果如下:
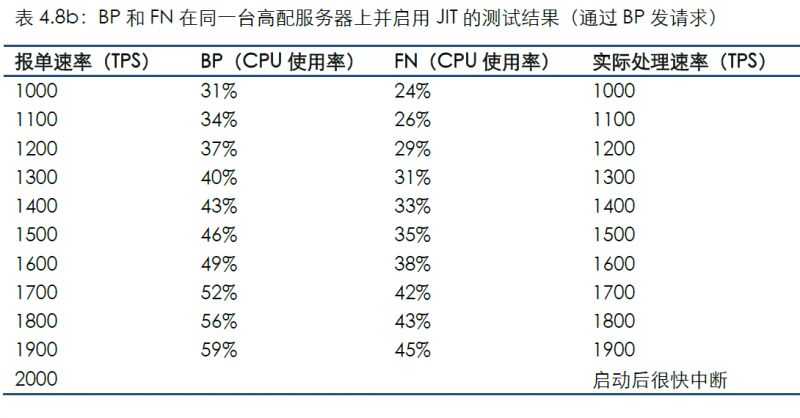
對比場景2可看到,CPU使用率大幅度降低,但在CPU并未完全使用的情況下發生測試中斷,證明JIT確實會影響系統穩定性


