 云妹導讀:
云妹導讀:
2008年10月31日,中本聰發布比特幣白皮書;2009年1月4日2時15分5秒(北京時間)比特幣創世塊問世。不鳴則已,一鳴驚人。區塊鏈技術就是這樣來到了人類的世界,成為當今最熱門的一項尖端科技。與許多新興技術一樣,它的發展道路并不是一帆風順的,但區塊鏈技術從未停止腳步,其底層基礎平臺層出不窮。
區塊鏈其實就是一種特殊的分布式數據庫。各個區塊鏈平臺最大的差異集中體現在對共識算法的優化和變革,而區塊鏈與傳統分布式數據庫的共識層決定了兩者的上層應用,區塊鏈中大多以BFT共識算法來解決各個節點在互不信任的情況下達成共識,而傳統的分布式數據庫一般都建立在各節點不存在作惡的情況下以CFT共識算法做數據一致性從而使各個節點達成共識。本文主要就兩類BFT和CFT中知名的共識算法做簡單介紹。

BFT(Byzantine Fault Tolerance),即拜占庭容錯,是分布式計算領域的容錯技術。拜占庭容錯來源于拜占庭將軍問題,是對現實世界的模型化。由于硬件錯誤、網絡擁塞或中斷以及遭到惡意攻擊等原因,計算機和網絡可能出現不可預料的行為。拜占庭容錯技術被設計用來處理現實存在的異常行為,并滿足所要解決的問題的規范要求。
區塊鏈網絡環境符合拜占庭將軍問題模型,有運行正常的服務器,有故障的服務器,還有破壞者的服務器。共識算法的核心是在正常的節點間形成對網絡狀態的共識。
POW(Proof of Work),即工作量證明,也稱挖礦,各個節點比拼硬件資源來獲得記賬權,比特幣與以太坊是最知名的兩大公有鏈。目前底層共識算法都為POW,2015年問世的以太坊對POW做了改進。
a) 比特幣中的POW
大致流程:
1) 生成礦工(coinbase)交易,并與其它所有準備打包進區塊的交易組成交易列表,生成Merkle根哈希值;
2) 把Merkle根哈希及其他相關字段組裝成區塊頭,將區塊頭的80字節數據作為工作量證明的輸入;
3) 不斷變更區塊頭中的隨機數Nonce,并對變更后的區塊頭做雙重SHA256哈希運算,將結果值與當前網絡的目標值做對比,如果小于目標值則解題成功,即POW完成。hash算法(hash算法(區塊頭))<目標值target,圖一為bitcoin POW源碼的核心部分,代碼目錄為src/rpc/mining.cpp。

▲圖一 bitcoin POW源碼▲
b) 以太坊中的POW
隨著專用挖礦設備ASIC礦機的出現,比特幣POW挖礦普通 PC 節點基本無法參與挖礦。以太坊針對比特幣的共識機制進行了一系列改進,重新設計了以太坊 POW (ETH)共識算法,稱之為Ethash。
Ethash主要特點是對內存大小和內存帶寬要求比較高,而對運算能力要求不高。通過生成一個占用大量內存空間,每三萬個區塊變更一次的DAG(Directed Acyclic Graph)數據集,限制高算力設備性能,降低運算優勢。
大致流程如圖二所示:
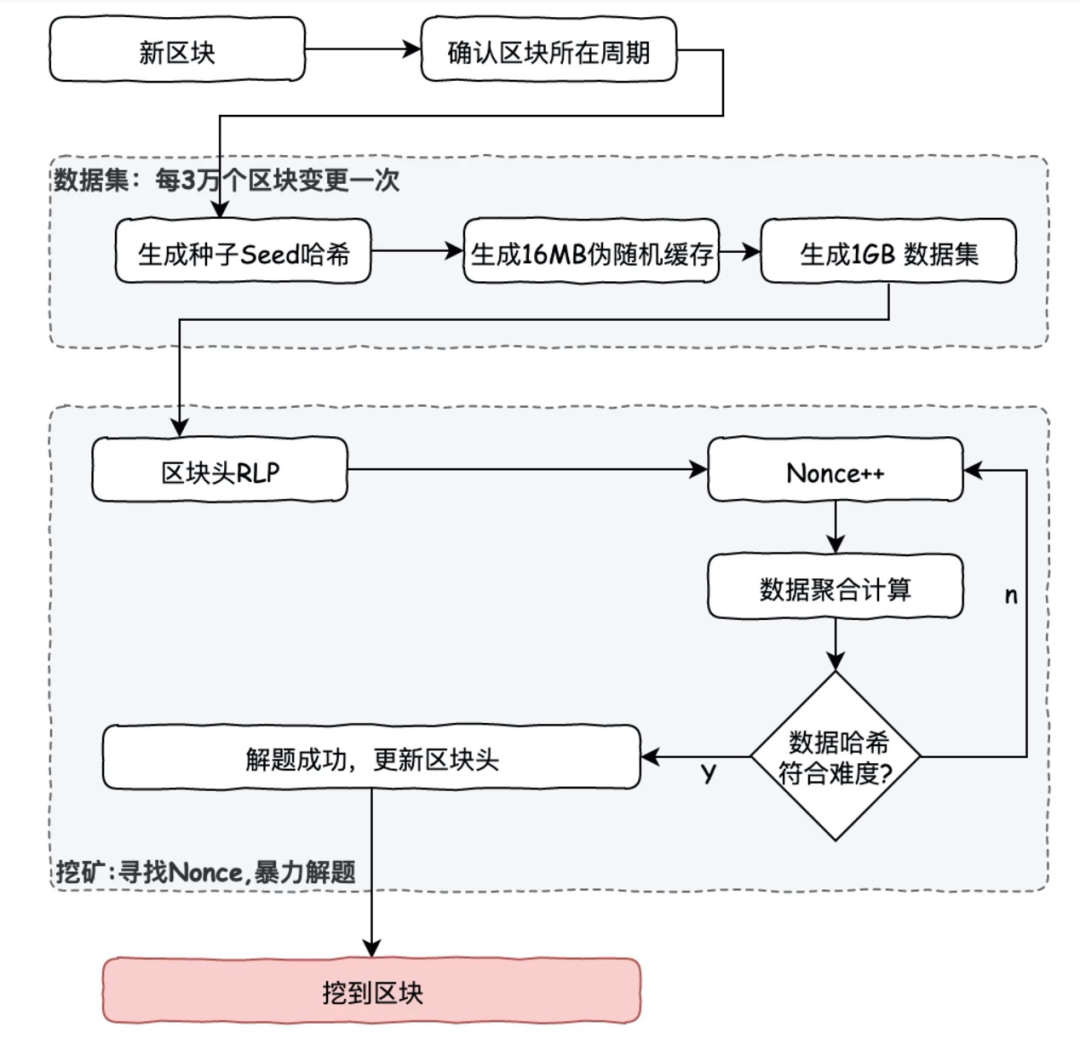
▲圖二 以太坊 ethash 挖礦流程圖▲
1) 對于每個區塊,先算出一個種子。種子的計算只依賴當前區塊信息;
2) 使用種子生成偽隨機數據集,稱為cache。輕客戶端需要保存cache;
3) 基于cache生成1GB大小的數據集,稱為the DAG。這個數據集的每一個元素都依賴于cache中的某幾個元素, 只要有cache就可以快速計算出DAG中指定位置的元素。完整可挖礦客戶端需要保存DAG;
4) 挖礦可以概括為從DAG中隨機選擇元素,然后暴力枚舉選擇一個nonce值,對其進行哈希計算,使其符合約定的難度,而這個難度其實就是要求哈希值的前綴包括多少個0。驗證的時候,基于cache計算指定位置DAG元素,然后驗證這個元素集合的哈希值結果小于某個值。
a) POS
由于POW算法在挖礦過程中對環境和電力的浪費極大,POS作為一種代替算法。POS(Proof of Stake)也稱股權證明,大致思想如下:
1) 把生產區塊的工作交給擁有更多代幣的人,擁有的越多,擁有記賬權概率越高;
2) 生產區塊的過程中得到代幣獎勵,可以理解為持有代幣帶來的利息;
3) 擁有大量代幣的人如果攻擊網絡,則會造成代幣價格的下降,對這些人是不利的,所以這些礦工攻擊網絡的意愿較低;
4) 生產區塊只需證明自己持有的代幣即可,不需要消耗多少算力,節約能源。
POS雖然一定程度上達到了節約資源的目的,但是引入了新的問題,如nothing at stake問題(由于構造新的區塊沒有算力成本,所以當區塊鏈出現分叉的時候,用戶有可能會傾向于同時在多個分支一起挖礦來獲得潛在更高的收益,這樣生成了大量的分支,破壞了一致性),極端的情況下會帶來中心化的結果,幣越多持幣時間越長,產生馬太效應。
b) DPOS
DPOS(Delegated Proof of Stake)委托權益證明,它的原理是讓每一個持有代幣的人進行投票,最終選出n個超級節點來進行生產區塊,當輪到超級節點時,沒能生成區塊,會被除名,網絡會選出新的超級節點來取代。
以公有鏈EOS DPOS為例,大致流程:
1) 持有token的用戶可以對候選的礦工進行投票;用戶在發生交易的時候,把自己的投票包含在交易中;
2) 得票最高的21個用戶被選為代表,在下一個周期中負責生產區塊;
3) 打亂代表的順序后,各代表開始依次生產區塊。每個代表都有自己固定的時間區間,需要在自己的區間中完成區塊的生產發布。目前這個區間是3秒,即在正常情況下每3秒產出一個區塊;
4) 每個代表在生產區塊的時候,需要找當時唯一的最長鏈進行生產,不能在其他分支上進行。
PBFT是Practical Byzantine Fault Tolerance的縮寫,意為實用拜占庭容錯算法。該算法是Miguel Castro和Barbara Liskov在1999年提出來的,解決了原始拜占庭容錯算法效率不高的問題,多應用在聯盟鏈場景中,如fabric0.6。
PBFT算法的無異常流程大致為圖三所示:
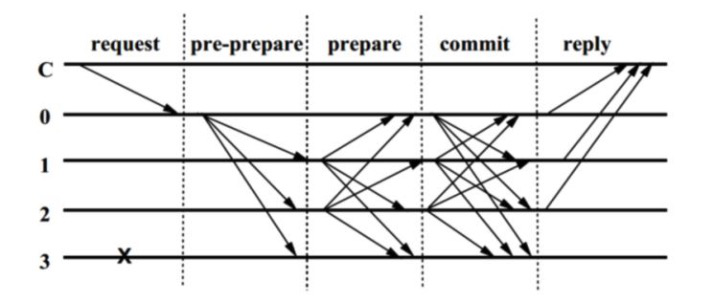
▲圖三 PBFT算法流程圖▲
1) 客戶端發送請求給主節點。
2) 主節點廣播請求給其它節點,節點執行PBFT算法的三階段共識流程。
3) pre-prepare階段:leader節點驗證請求消息m的有效性,并在其視圖內為該請求分配序列號,并向所有其他節點廣播關于該分配的pre-prepare消息。
4) prepare階段:非leader節點驗證請求消息的有效性,并接受序列號。若該節點同意該分配方案,則向其他所有節點廣播出相應的prepare消息;這一階段其實是要求所有節點達成全局一致的順序。
5) commit階段:節點一旦收到來自集群2f+1個的prepare簽名消息后,則向其他所有節點廣播出commit消息;這一階段,所有節點已經對順序達成一致,并對收到請求已做確認。
6) 節點收到來自集群的2f+1個commit消息后,執行請求、落盤,并返回消息給客戶端。
7) 客戶端收到來自f+1個節點的相同消息后,代表共識已經正確完成(f代表能容忍反叛節點或者壞節點的個數,總共3f+1個節點)。

CFT(Crash Fault Tolerance),即故障容錯,是非拜占庭問題的容錯技術。Paxos問題是指分布式的系統中存在故障,但不存在惡意節點的場景(即可能消息丟失或重復,但無錯誤消息)下的共識達成問題,是分布式共識領域最為常見的問題。最早由Leslie Lamport用Paxon島的故事模型來進行描述而得以命名。解決Paxos問題的算法主要有Paxos系列算法和Raft算法,Paxos算法和Raft算法都屬于強一致性算法。
Paxos算法的基本思路類似兩階段提交:多個提案者先要爭取到提案的權利(得到大多數接受者的支持)。成功的提案者發送提案給所有人進行確認,得到大部分人確認的提案成為批準的結案。
Paxos協議有三種角色:
Proposer(提議者)提出提案 (Proposal)。Proposal信息包括提案編號 (Proposal ID) 和提議的值(Value),Acceptor(決策者)參與決策,回應Proposers的提案。收到Proposal后可以接受提案,若Proposal獲得多數Acceptors的接受,則稱該Proposal被批準,Learner(決策學習者)參與決策,從Proposers/Acceptors學習最新達成一致的提案(Value)。
Paxos是一個兩階段的通信協議,Paxos算法的基本流程如圖四所示:
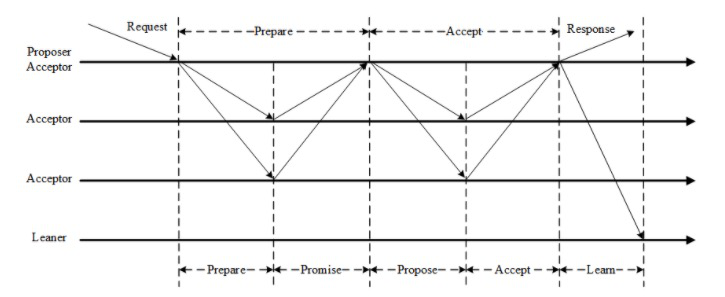
▲圖四 Paxos算法流程圖▲
1) Proposer生成Proposal ID n,可采用時間戳+Server ID生成的唯一的Proposal ID;
2) Proposer向所有Acceptors廣播Prepare(n)請求;
3) Acceptor比較n和minProposal(之前接受的提議請求),如果n>minProposal,minProposal=n,并且將 acceptedProposal 和 acceptedValue 返回;
4) Proposer接收到過半數回復后,如果發現有acceptedValue返回,將所有回復中acceptedProposal最大的acceptedValue作為本次提案的value,否則可以任意決定本次提案的value;
5) 到這里可以進入第二階段,廣播Accept (n,value) 到所有節點;
6) Acceptor比較n和minProposal,如果n>=minProposal,則acceptedProposal=minProposal=n,acceptedValue=value,本地持久化后,返回;否則,返回minProposal;
7) 提議者接收到過半數請求后,如果發現有返回值result >n,表示有更新的提議,跳轉到1;否則value達成一致。
有感于Paxos的晦澀難懂,Ongaro在2014年提出了更容易理解的Raft算法。它將一致性分解為多個子問題:Leader選舉(Leader election)、日志同步(Log replication)、安全性(Safety)、日志壓縮(Log compaction)、成員變更(Membership change)。
Raft算法由leader節點來處理一致性問題。leader節點接收來自客戶端的請求日志數據,然后同步到集群中其它節點進行復制,當日志已經同步到超過半數以上節點的時候,leader節點再通知集群中其它節點哪些日志已經被復制成功,可以提交到raft狀態機中執行。
集群中的節點只能處于leader、follower、candidate這3種狀態之一。初始狀態所有節點都是follower狀態,follower想變成leader必須先成為candidate,然后發起選舉投票;如果投票不足,則回到follower狀態;如果投票過半,則成為leader;成為leader后出現故障,若故障恢復后已有新leader,則自動下臺,回歸follower狀態。
Raft還引入了term的概念用于及時識別過期信息,類似于zookeeper中的epoch;term值單向遞增,每個term內至多一個leader;若不同term的信息出現沖突,則以term值較大的信息為準。
Raft還采用了心跳包和超時時間,leader為了保持自己的權威,必須不停地向集群中的其他節點發送心跳包;一旦某個follow在超過了指定時間(election timeout)仍沒有收到心跳包,則就認為leader已經掛掉,自己進入candidate狀態,開始競選leader。
Raft的leader選舉是通過heartbeat和隨機timeout時間來實現的;而日志復制(log replication)階段是以強leadership來實現的:leader接收client的command,append到自身log中,并將log復制到其他follower;而raft對安全性的保證是通過只有leader可以決定是否commit來實現的。

從Paxos、Raft到PBFT,從POW到POS,再到目前各種各樣的Paxos變種、Raft變種、BFT類混合新算法、及各種基于POW算法的改良,分布式一致性算法在不斷發展、完善、進化。甚至各大公司也在結合自己的業務實際,研發各種適合自己場景的分布式一致性算法,對共識算法的思考,也在不算深入,從傳統的分布式封閉的網絡中的共識,到有準入規則的聯盟鏈,再到人人都可參與的公有鏈開放網絡環境中的共識機制,所需要解決的問題越來越復雜,應對的挑戰也越來越嚴峻,我們還有很長的路要走。
參考資料:
*1. http://www.scs.stanford.edu/14au-cs244b/labs/projects/copeland_zhong.pdf
*2. https://people.cs.umass.edu/~emery/classes/cmpsci691st/scribe/lecture17-byz.pdf
*3. https://lamport.azurewebsites.net/tla/byzsimple.pdf
*4. https://blockonomi.com/practical-byzantine-fault-tolerance/
*5. https://medium.com/@VitalikButerin/the-meaning-of-decentralization-a0c92b76a274
*6. https://bitcoin.org/bitcoin.pdf
*7. https://en.wikipedia.org/wiki/Proof-of-work_system
*8. https://bitnodes.earn.com/
*9. https://www.giottus.com/Bitcoin
*10. https://www.nichanank.com/blog/2018/6/4/consensus-algorithms-pos-dpos
*11. https://en.bitcoinwiki.org/wiki/DPoS
*12. https://amplab.github.io/cs262a-fall2016/notes/21-Paxos-Raft.pdf
*13. https://www.the-paper-trail.org/post/2012-03-25-flp-and-cap-arent-the-same-thing/
*14. https://github. com/ethereum/wiki/wiki/White-Paper
15. https://hyperledger-fabric-cn.readthedocs.io/zh/latest/index.html



