區塊鏈的核心之一是共識算法。因為各類區塊鏈采用的共識算法不同,所以在運行性能、容災容錯性等方面的表現也不盡相同,進而決定了不同鏈適用場景上的差異。本期我們將挑選一些目前比較流行的共識算法進行探討。目前較為常見的共識算法有POW、POS、DPOS、PBFT、RBFT,除此之外還有Hyperledger Fabric主推的Kafka、Raft,以下是各共識算法及對應的代表鏈。POW(Proof Of Work) - 工作量證明所有競爭記賬方需要通過大量運算對一道算法題求解,最先得到問題正確答案的一方將獲得本輪的記賬權,計算機算力越高,越有機會獲得記賬權,算力是計算機硬件(CPU、GPU等)提供的,要耗費 電力,造成能源的大量浪費,主要使用在無信任關系的公鏈上,出塊慢。POS (Proof Of Stake) - 權益證明POS記賬權由幣齡決定,幣齡怎么獲得呢,比如你有1W個Token,經過一段時間之后,比如10天,那么你的幣齡為1W x 10 = 10W。假如此時你的幣齡是網絡節點中最大的,那么你就獲得了記賬權,自然能拿到記賬的Token獎勵,所以這種模式下擁有Token數量越多的人越有機會獲得記賬權。這種共識的優點是持有Token數量越多的人會越自覺維護鏈的秩序,因為作惡成本高。 共識過程相比POW更快,因為POS通過幣齡來確定獲得記賬權的難度遠低于POW通過全網大量運算得到正確答案的難度。缺點是去中心化程度不高,因為幣齡的機制決定了記賬權容易被大資本掌控, 貧富差距容易變大。在POS機制下,Token持有量少的人很難獲得記賬權,也就無法獲得記賬獎勵,而Token大戶很容易形成記賬權壟斷,對鏈的生態發展是不利的。DPOS(Delegated Proof Of Stake) - 委托權益證明相當于POS的升級版,在節點中增加了委托人概念,各網絡節點均可以參加投票,選出節點代表,由這些得票高的節點代表輪流記賬,相對POS去中心化程度有所好轉,出塊時間更短,效率更高。PBFT(Practical Byzantine Fault Tolerance) - 實用拜占庭容錯PBFT是區塊鏈共識機制的主流算法之一,經過優化,將拜占庭容錯算法從指數級別降低到多項式級別,支持在網絡弱同步性情況下,在叛變節點不超過總節點的1/3情況下(最壞需要F+1輪交互,F為叛變節點),確保整個系統達成共識。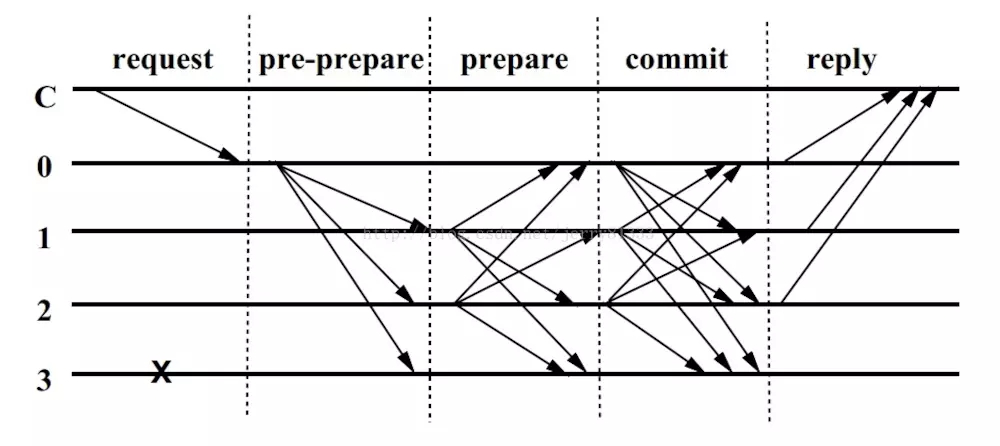
C為客戶端,0 ~3 表示從節點,特別的,0為主節點,3 為故障節點。如上圖所示,pbft算法的主要工作流程分為三階段:2)當主節點接收到請求后,啟動三階段的協議以向各從節點廣播請求。主節點給收到的請求分配編號,然后發出預準備消息<<PRE-PREPARE,view,n,digest>,message>給其他從節點。view:當前視圖的編號。當因為主節點故障而發生視圖輪換時,v值相應增加n:當前請求的編號。主節點收到客戶端的每個請求都以一個編號來標記。注意,僅當滿足以下條件,各從節點才會接受預準備消息:1、請求和預準備消息的簽名正確,并且digest與message的摘要一致。3、該從節點從未在視圖v中接受過序號為n的消息,或者接受過但是摘要d和消息m需要和上次消息的一樣。從節點接收PRE-PREPARE消息,檢查消息的合法性,檢查通過后,向其他節點廣播prepare消息<PREPARE,view,n,digest,id>,帶上本節點的id,同時接受來自其他節點的PREPARE消息,收到PREPARE消息后同樣進行合法性檢查。一旦收到2f個不同節點的prepare消息,就代表prepare階段已經完成。廣播commit消息<COMMIT,view,n,digest,id>,告訴其他節點某個提案n在視圖v里已經處于準備狀態,如果它收到了2f+1條commit消息(包括自身的一條,這些來自不同節點的commit消息攜帶相同的編號n和view v),則說明提案通過。該請求就會被節點執行。在完成請求的操作之后,節點向客戶端發送回復。客戶端等待來自不同節點的響應,若有f+1個響應相同,則該響應即為運算的結果。通常在采用PBFT的共識機制下,主節點(Replica)負責將來自客戶端的交易請求進行排序,然后按順序發送給備份節點(Backups)。主節點擁有比其它備份節點更大的權利,一旦主節點出現問題,會導致系統中比較大的延遲甚至無法達成共識。國內自主研發的井通Jingtum聯盟公鏈后續采用的RBFT共識機制針對這一缺陷進行了改進。RBFT參考借鑒了RAFT中的選舉機制,采用投票表決方式進行節點選舉,無需搶奪記賬權,保證各個共識節點權益的公平性。與PBFT的不同之處主要在于,在節點的選擇上使用了隨機數。PBFT本是有限節點記賬的共識機制,系統中只有被認可的節點才能作為記賬節點。加入隨機數之后,可以將靜態的節點選擇變為動態,使節點增多。RBFT算法類似于DPOS,但支持的節點數目遠遠超過EOS(21個),這可以使系統在不犧牲性能的前提下提高安全性。 以上POW、POS、DPOS、PBFT、RBFT是較常見的主流共識算法,接下來我們看看Hyperledger Fabric主推的Kafka和Raft。Kafka是一款基于zookeeper協調的領導者、跟隨者模型的分布式消息系統,Hyperledger fabric 1.4以前版本主要通過kafka進行共識。Hyperledger Fabric是由IBM公司主導開發的一個面向企業級客戶的區塊鏈項目,后貢獻給開源非營利組織 Hyperledger 基金會,Fabric是需要許可型平臺,即適用聯盟鏈及私有鏈,并且它會刪除“并不適合企業場景”的特性, 需要注意的是fabric 2.0后將會去掉Kafka。
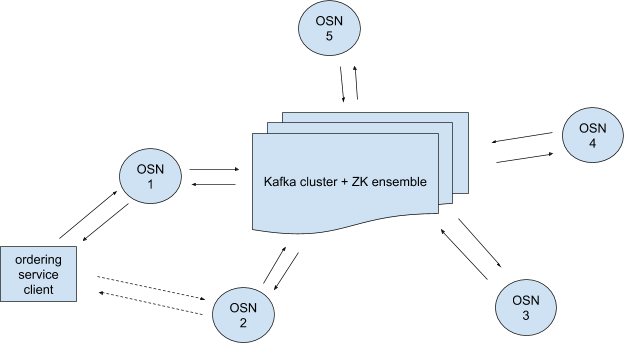 圖1
圖1
圖1中,一個訂購服務,由5個訂購服務節點(OSN-n)和一個Kafka集群組成。訂購服務客戶端可以連接到多個OSNs。注意,OSNs之間不直接通信。
這些有序服務節點(OSNs) (1)執行客戶端身份驗證,(2)允許客戶端使用簡單的接口寫入或讀取鏈,(3)它們還為重新配置現有鏈或創建新鏈的配置事務執行事務過濾和驗證。
Kafka中的消息(記錄)被寫入主題分區。一個Kafka集群可以有多個主題,每個主題可以有多個分區(圖2)。每個分區都是一個有序的、不可變的記錄序列,它被不斷地追加來者客戶端的交易記錄。
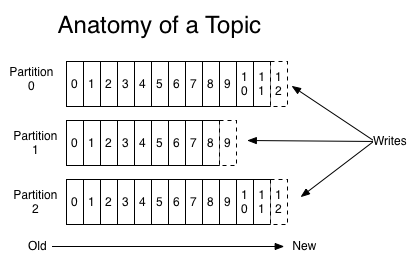
圖2
現在看看Fabric中Kafka的完整工作流程:
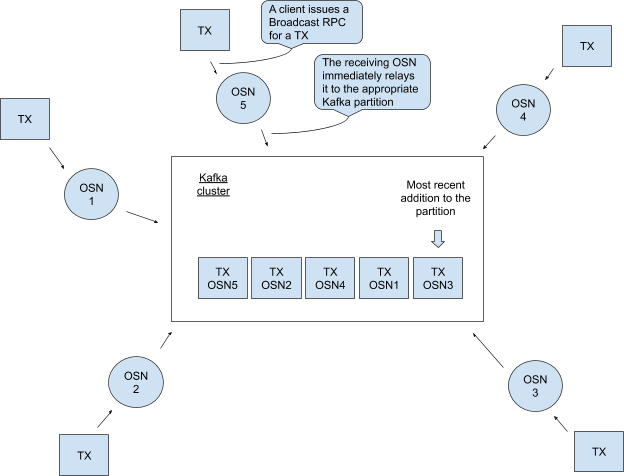
排序服務客戶端將收集到的記錄發往各OSN,OSN將批量交易打包成block,并生成用于驗證的簽名,同時為block分配kafka上的partition分區及partition中的offset偏移量。OSN將block發送至kafka集群中指定的partition中對應偏移量的位置上。
各OSN按相同順序從partition中讀取block發往對應channel中的各peers驗證節點進行驗證。
部署方面,由于Kafka集群大都需要部署到大型公司、集團總部或者云廠商,保證高計算能力和高可用,當Kafka所在的聯盟鏈間各個企業不存在一強多弱,真正是幾家平等的企業在合作時,在技術設計中就會存在一個比較大的疑惑,Kafka排序服務應該部署在哪里呢?也許部署到公有云上是一個選擇,但當云廠商本身是利益的相關方呢?
Raft
Raft與Kafka一樣也是領導者、跟隨者模型,以下是大致執行過程
節點初始都是跟隨者follower,每個follower都有自己的timeout,時間范圍在150ms - 300ms之間,timeout后若未檢測到來自Leader的心跳消息,則follower自動升級為Candidate(候選者),并向網絡中其它節點發送選舉自己為Leader的投票消息。
當收到大部分的票數后,候轉節點變為Leader,同步消息至網絡中其它節點以確認新的Leader,之后開始處理Leader收到的來自客戶端的消息。
Leader將收到的來自客戶端的消息記錄至本地日志中,并同步至各follower節點,各節點確認沒問題后返回確認消息給Leader,Leader返回處理結果給客戶端,同時更新日志中的消息至持久化存儲區域,并且同步給各follower。
Raft具體執行過程可參考鏈接 http://thesecretlivesofdata.com/raft
但是Raft用于區塊鏈共識的前提是“假設將軍中沒有叛軍”,簡單通俗的說法就是在分布式系統中機器節點可能會掛,網絡可能延遲、重復或者丟失,但是機器節點不會作惡,傳遞的消息也不會被篡改,區塊鏈的重要特性之一為不可篡改,而在無拜占庭容錯的情況下,這一特性顯然無法完全得到保障,一但出現節點作惡,對鏈與應用帶來的影響無法想象。
在上文對各共識算法分別進行了原理探討后,我們簡單歸納整理如下:
共識算法 | 代表鏈 |
POW | 適用無信任授權區塊鏈,如BTC(比特幣)、ETH(以太坊),優點是完全去中心化、公平公正,安全,缺點是需要消耗大量算力,浪費能源,出塊慢,效率低。 |
POS | 較適用聯盟鏈、私鏈,優點是比POW出塊更快,缺點是去中心化不強,通過持幣量越高,越有話語權,很容易形成對記賬權的壟斷,不利于區塊鏈生態發展。 |
DPOS | POS的PLUS版,適用聯盟鏈、私鏈,優點是共識節點數相對穩定,比POS出塊更快。 |
PBFT | 適用于聯盟鏈、私鏈,優點是支持拜占庭容錯,能提供較穩定服務,缺點是主節點權利太大,一旦主節點出現問題,會導致系統中比較大的延遲甚至無法達成共識,并且支持節點數較少。 |
RBFT | 適用于聯盟鏈、私鏈,加入了隨機數概念,削弱了主節點的權利,能啟用更多的靜態節點,性能更高,出塊時間穩定控制在秒級,程序接入簡單,耦合低。 |
Kafka | 適用于私鏈,優點是方便對交易排序,性能高。缺點是中心化程序較高,且不支持拜占庭容錯。 |
Raft | 與Kafka相似,適用于私鏈,優點是支持拜占庭,但不支持拜占庭容錯,即在分布式系統中機器節點可能會掛,網絡可能延遲、重復或者丟失,但是機器節點不會作惡,傳遞的消息也不會被篡改。 |
結語:
企業對鏈的選擇,其實就是對共識算法的選擇,每種共識算法自有其適用的場景,企業可以根據自身情況進行擇優選擇。我們的認知還有很多疏漏之處,歡迎各位朋友斧正。
版權申明:本內容來自于互聯網,屬第三方匯集推薦平臺。本文的版權歸原作者所有,文章言論不代表鏈門戶的觀點,鏈門戶不承擔任何法律責任。如有侵權請聯系QQ:3341927519進行反饋。


